深度残差网络ResNet初探
微软亚洲研究院 Kaiming He 博士在 2015 年凭借深度残差网络 Deep Residual Network (DRN) 在 Imagenet 比赛的识别、检测和定位三个任务、以及 COCO 比赛的检测和分割任务上都获得了冠军。论文《Deep Residual Learning for Image Recognition》获得 2016 CVPR best paper,ResNet因此声名大噪,很大程度上引发了 deep network 的革命。
问题提出
现有的深度学习思想可能认为深层的网络一般会比浅层的网络效果好,如果要进一步地提升模型的准确率,最直接的方法就是把网络设计得越深越好,这样模型的准确率也就会越来越准确。例如在图像处理任务中,CNN 能够提取 low / mid / high-level 的特征,网络的层数越多,意味着能够提取到不同 level 的特征越丰富。越深的网络提取的特征越抽象,越具有语义信息。
Kaiming 博士在论文中做了这样一组实验:在 CIFAR-10 数据集上分别训练了一个 20 层和 56 层的 plain network (卷积、池化、全连接构成的传统 CNN ),发现 56 层网络的训练误差和测试误差都大于 20 层网络的训练误差,即网络层数加深时,模型效果却越来越差,在训练集上的准确率甚至下降了,因此这个显然不是由于 overfitting 导致的,因为 overfitting 应该表现为在训练集上效果更好才对。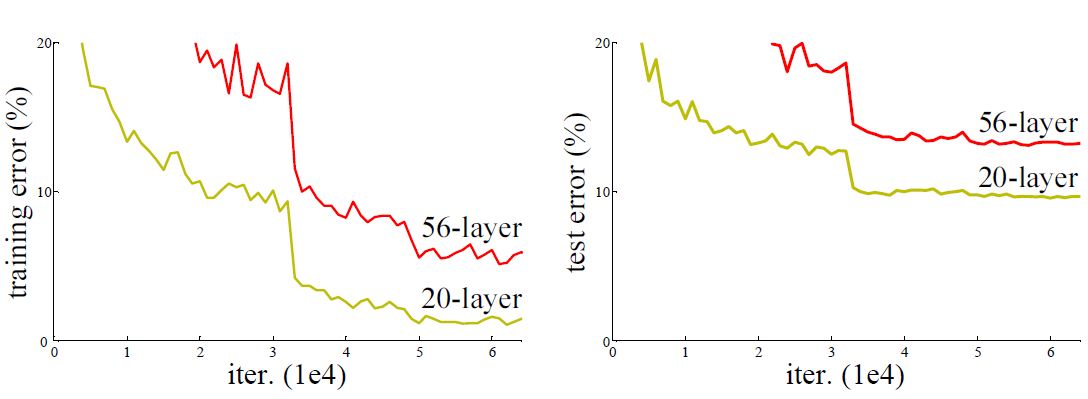
分析思考
1.为什么不能直接简单地增加层数?
神经网络的深度加深,一个众所周知的问题就是梯度的消失和爆炸 (gradients vanishing / gradients exploding),它会导致深层的网络参数得不到有效的校正信号或使得训练难以收敛,通过正则化初始化或者中间的正则化层 (Batch Normalization) 方法可以得到有效的缓解,但并不能解决这里提出的问题。
2.为什么网络层数加深时,网络的性能反而下降?
我们假设现在有一个浅层 (假设层数为 n) 的神经网络plain network A ,具有比较理想的输出结果,现在在这个神经网络的后边再加 m 层得到一个新的神经网络 B,我们发现输出结果的准确度反而下降了。这是不合理的,因为如果后边加上的那 m 层是对前 n 层的输出结果做恒等映射 (identity mapping),至少 B 也能和 A 的性能持平才对。但是实验的结果表明现在的求解方法并不能得到理想的结果,这说明 B 网络在学习恒等映射的时候出了问题,也就是传统网络 (plain networks) 很难去学习恒等映射,这就是所谓的退化 (degradation) 现象。
核心思想
如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络,现在要解决的就是如何学习恒等映射函数。但是直接让一些层去拟合一个潜在的恒等映射函数 H(x) = x 是很困难的,但是如果使用残差函数 H(x) = F(x) + x,F(x) = H(x) - x,如果能使 F(x) = 0,H(x) 就是恒等映射。
网络输入是 x,网络的输出是 F(x),网络要拟合的目标是 H(x),传统网络的训练目标是 F(x) = H(x)。
残差网络,则是把传统网络的输出 F(x) 处理一下,加上输入 x,变成 F(x) + x 作为最终的输出,训练目标是 F(x) = H(x) - x。
现在我们要训练一个深层的网络,它可能过深,假设存在一个性能最强的完美网络 N,与它相比我们的网络中必定有一些层是多余的,那么这些多余的层的训练目标是恒等变换,只有达到这个目标我们的网络性能才能跟 N 一样。对于这些需要实现恒等变换的多余的层,要拟合的目标就成了 H(x) = x,在传统网络中,网络的输出目标是 F(x) = x,这比较困难,而在残差网络中,拟合的目标成了 x - x = 0,网络的输出目标为 F(x) = 0,这比前者要容易得多。
这里的 F(x) + x 为什么是 x 而不是其他值?因为多余的层的目标是恒等变换,即 F(x) + x = x,那 F(x) 的训练目标就是 0,比较容易。如果是其他,比如 x/2 ,那 F(x) 的训练目标就是 x/2,是一个非 0 的值,比 0 难实现。Kaiming 博士的另一篇文章[2]中探讨了这个问题,对6种结构的残差结构进行实验比较证明 F(x) 加上输入值 x 的效果最好。
Residual Block

在上图的残差网络结构图中,通过“shortcut connections (捷径连接)”的方式,直接把输入x传到输出作为初始结果,输出结果为 H(x) = F(x) + x,当 F(x) = 0 时,那么 H(x) = x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,即所谓的残差F(x) = H(x) - x,因此,后面的训练目标就是要将残差结果逼近于 0,使得随着网络加深,准确率不下降。
它有二层,如下表达式,其中 $\sigma$ 代表非线性函数ReLU:
$$\mathcal{F} = W_2\sigma(W_1x)$$
然后通过一个 shortcut connection,和第 2 个 ReLU,获得输出 y:
$${y}= \mathcal{F}({x}, {W_{i}}) + {x}.$$
F(x) 与 x 相加就是逐元素相加,但是如果两者维度不同,需要给 x 执行一个线性变换来匹配维度,如下式:
$${y}= \mathcal{F}({x}, {W_{i}}) + W_s{x}.$$
实验证明,这个残差块往往需要两层以上,单单一层的残差块 $y = W_1x + x$ 并不能起到提升作用。
这种残差跳跃式的结构,打破了传统的神经网络 n - 1 层的输出只能给 n 层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向 (后来的 DenseNet)。至此,神经网络的层数可以超越之前的约束,达到几十层、上百层甚至千层,为高级语义特征提取和分类提供了可行性。
Model Structure
作者由 VGG19 设计出了 plain network 和 Resnet-34,如下图中部和右侧网络。
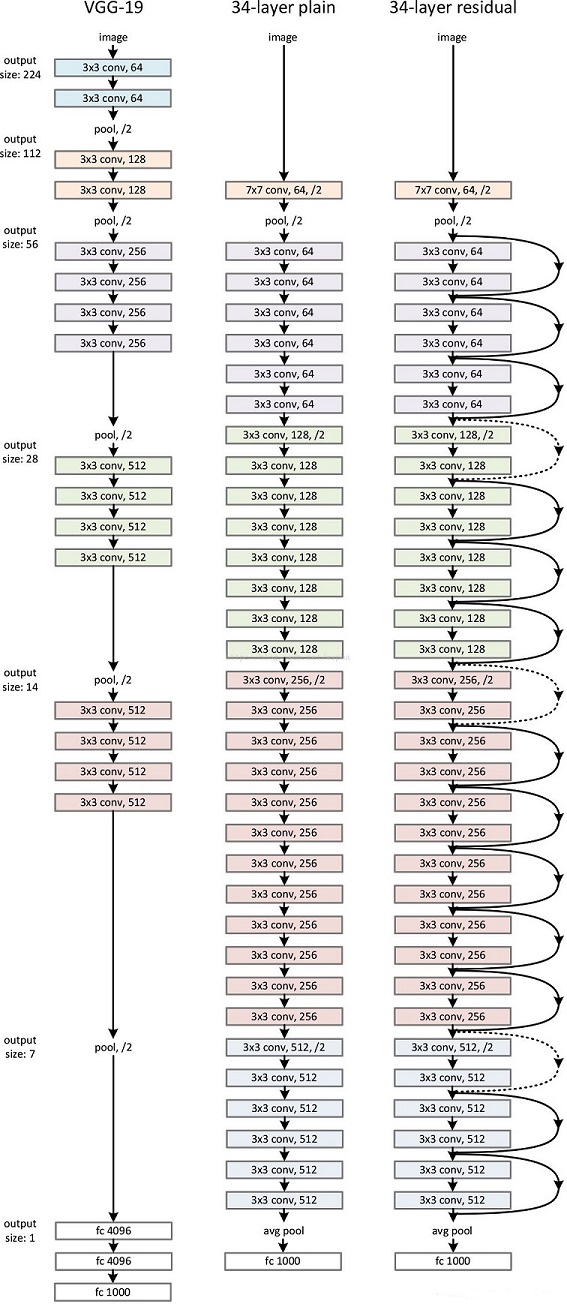
- 对于输出 feature map 大小相同的层,有相同数量的 filters,即 channel 数相同;
- 当 feature map 大小减半时(pooling),filters数量翻倍。
- 对于残差网络,维度匹配的shortcut连接为实线,反之为虚线。维度不匹配时,同等映射有两种可选方案:
- 直接通过 zero padding 来增加维度(channel)。
- 乘以 W 矩阵投影到新的空间。实现是用 1 x 1 卷积实现的,直接改变 1 x 1 卷积的 filters 数目。这种会增加参数。
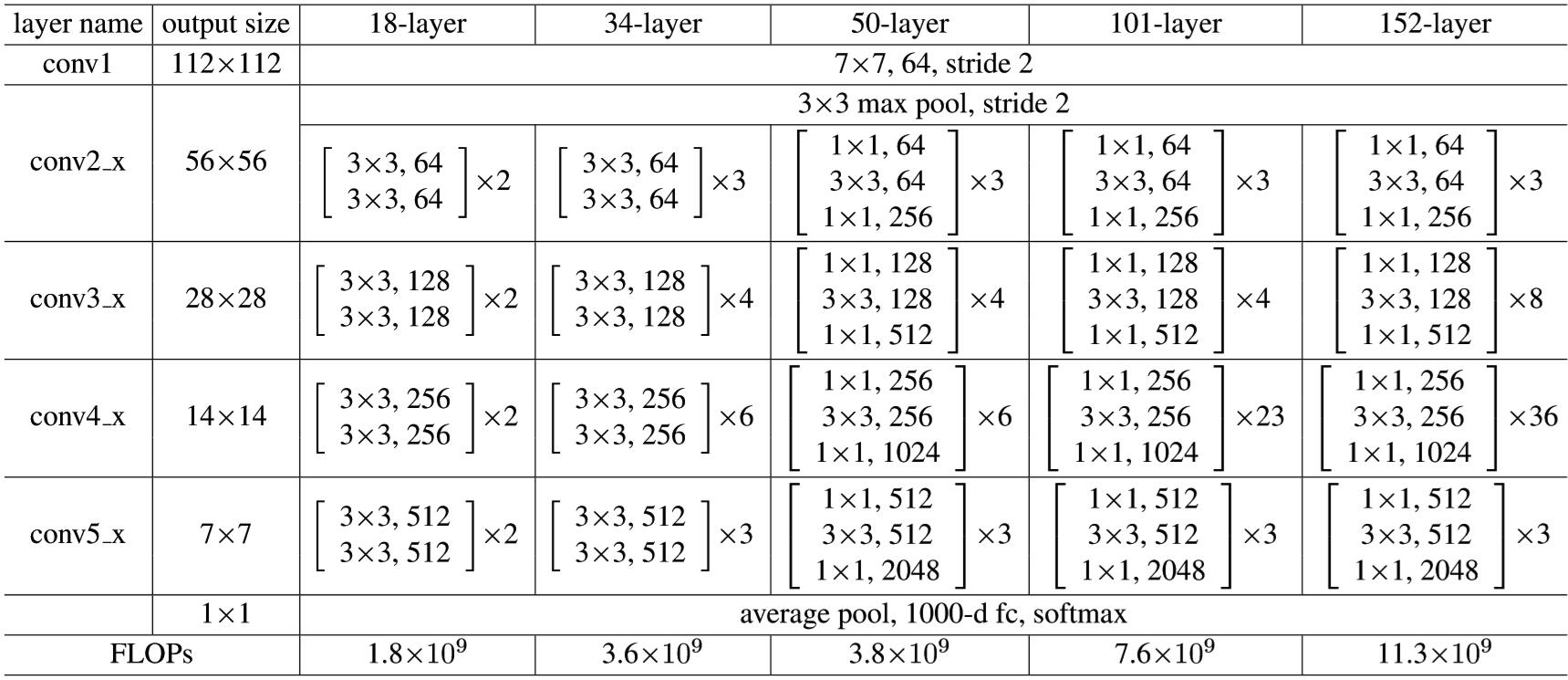
下图是Resnet对应于ImageNet的结构框架。中括号中为残差块的参数,多个残差块进行堆叠。下采样由 stride 为 2 的 conv3_1、conv4_1 和 conv5_1 来实现。
Bottle neck
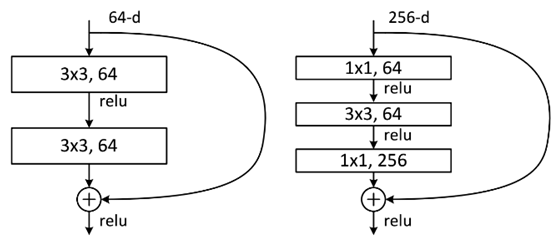
考虑到时间花费和降低参数的数目,将原来的 Residual Block (残差学习结构) 改为 Bottleneck 结构,如上图。首端和末端的 1 x 1 卷积用来削减和恢复维度,相比于原本结构,只有中间 3 x 3 成为瓶颈部分。两种结构分别针对 ResNet-34 (左图)和 ResNet-50/ 101 / 152(右图)。
左图是两个 3 x 3 x 256的卷积,参数数目: 3 x 3 x 256 x 256 x 2 = 1179648;右图是第一个 1 x 1 的卷积把 256 维通道降到 64 维,然后在最后通过 1 x 1 卷积恢复,整体上用的参数数目:1 x 1 x 256 x 64 + 3 x 3 x 64 x 64 + 1 x 1 x 64 x 256 = 69632,右图的参数量比左图减少了 16.94 倍。对于常规的ResNet,可以用于34层或者更少的网络中(左图),对于更深的网络(如50 / 101 / 152层),则使用右图,其目的是减少计算和参数量。
TensorFlow实现
- KaimingHe/deep-residual-networks
- wenxinxu/resnet-in-tensorflow
- tensorpack/examples/ResNet
- ry/tensorflow-resnet
Python示例
1 | def residual_block(x, out_channels, down_sample, projection=False): |
参考资料
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition (pp.770-778). IEEE Computer Society.
- https://www.jianshu.com/p/e58437f39f65
- https://zhuanlan.zhihu.com/p/32085715
- https://my.oschina.net/u/876354/blog/1622896
- https://blog.csdn.net/wspba/article/details/57074389
深度残差网络ResNet初探